



Dalam dunia pemrograman, kita sering memulainya dengan menulis Hello World di terminal. Para artikel ini, kita akan melakukan projek sederhana pengenalan angka tulisan tangan dengan data MNIST. Projek ini dikenal juga sebagai "Hello World" for computer vision.
Keras adalah library open source yang mudah digunakan. Dikembangkan oleh François Chollet, Keras dirancang untuk memungkinkan eksperimen deep neural network dengan mudah. Keras mensupport banyak backend, termasuk TensorFlow dan PyTorch. Keras sangat populer karena penggunaannya yang mudah baik oleh pemula ataupun ahli dalam deep learning. Seorang developer yang menggunakan keras bisa dengan cepat membuat prototipe dan membangun model neural network hanya dengan beberapa baris kode saja.
Persiapan Data
Persiapan data merupakan langkah penting dalam proyek machine learning apa pun. Pada tahap inilah terjadi transformasi dari yang awalnya data mentah menjadi format yang sesuai untuk dipelajari oleh model.
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import layers
Mengimpor Library: Kita mulai dengan mengimpor library yang diperlukan: numpy untuk operasi numerik, matplotlib.pyplot untuk plotting, dan keras untuk membangun model.
# Model / data parameters
num_classes = 10
input_shape = (28, 28, 1)
Menetapkan Parameter: Kita mendefinisikan jumlah kelas (digit 0-9) dan bentuk input gambar (28x28 piksel, 1 channel untuk grayscale).
# Load the data and split it between train and test sets
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
Memuat Data: Kita memuat dataset MNIST, yang dibagi menjadi pelatihan dan pengujian. Dataset ini berisi gambar digit tulisan tangan dan label yang sesuai.
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
Normalisasi Data: Kita lakukan normalisasi data gambar ke rentang [0, 1] dengan membaginya dengan angka 255 (angka maksimal pada gambar rgb). Ini membantu dalam proses pelatihan karena nilai-nilai diskalakan ke dalam rentang yang lebih kecil.
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
Mengubah Bentuk Data: Kita mengubah bentuk data untuk menyertakan dimensi channel, sehingga data yang awalnya (28,28) menjadi (28, 28, 1). Hal ini diperlukan karena lapisan CNN di Keras mengharapkan input memiliki bentuk ini.
print("x_train shape:", x_train.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")
Mencetak Shape Data: Kita mencetak ukuran data pelatihan dan pengujian untuk memverifikasi kesesuaian data.

# Convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
One-Hot Encoding: Kita mengkonversi label kelas ke vektor one-hot encoded. Ini diperlukan untuk tugas klasifikasi kategorikal karena mengubah label menjadi format matriks biner dan agar model tidak mengira label pada data (angka 1-9) sebagai suatu urutan.
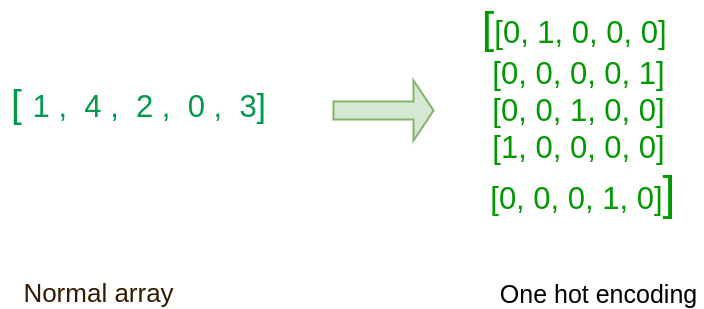
Memvisualisasikan Data
Visualisasi data membantu kita dalam memahami karakteristik data yang akan kita prediksi untuk pelatihan.
# Plot the first 25 training images
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i].reshape(28, 28), cmap=plt.cm.binary)
plt.xlabel(np.argmax(y_train[i]))
plt.show()
Visualisasi Data Pelatihan: Kita memplot 25 gambar pertama dari set pelatihan. Setiap gambar ditampilkan dengan label yang sesuai.

Pembuatan Model
Pembuatan model adalah proses mendefinisikan arsitektur nerual network. Di sini juga kita mendefinisikan spesifikasi dari lapisan dan konfigurasi mereka.
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
Definisi Model: Kita mendefinisikan model Sequential dengan lapisan-lapisan berikut:
Lapisan input yang menentukan bentuk input.
Dua lapisan konvolusional (
Conv2D) dengan aktivasi ReLU.Dua lapisan max pooling (
MaxPooling2D) untuk downsampling input.Lapisan flatten untuk mengubah matriks 2D menjadi vektor 1D.
Lapisan dropout (
Dropout) untuk mencegah overfitting.Lapisan dense output (
Dense) dengan aktivasi softmax untuk mengeluarkan probabilitas kelas.
model.summary()
Ringkasan Model: Mencetak ringkasan model berguna untuk melihat arsitektur dan jumlah parameter di setiap lapisan. Proses ini membantu dalam memahami kompleksitas model.

Melatih Model
batch_size = 128
epochs = 15
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
Menyusun Model: Kita melakukan compile model menggunakan fungsi loss categorical crossentropy, optimizer Adam, dan metrik akurasi.
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
Melatih Model: Model yang sudah dicompile kemudian dilatih dengan jumlah epoch dan batch size yang sudah ditetapkan. Kita juga menyisihkan 10% data pelatihan untuk validasi.

Mengevaluasi Model
Evaluasi melibatkan pengujian model yang telah dilatih pada data yang belum terlihat untuk memeriksa kinerjanya.
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])
Mengevaluasi Model: Kita mengevaluasi model pada data pengujian dan mencetak loss dan akurasi pengujian. Ini membantu dalam memahami seberapa baik model menggeneralisasi ke data baru.

Memvisualisasikan Contoh yang Salah Diprediksi
Dari evaluasi model, kita mendapatkan akurasi 99%, ini merupakan hasil yang bagus. Namun seperti apa 1% data yang salah diprediksi tersebut? Tahap terakhir kita lakukan visualisasi pada data-data yang salah diprediksi.
# Predict the values from the test dataset
y_pred = model.predict(x_test)
y_pred_classes = np.argmax(y_pred, axis=1)
y_true = np.argmax(y_test, axis=1)
# Errors are difference between predicted labels and true labels
errors = (y_pred_classes - y_true != 0)
# Get the indices of the misclassified examples
misclassified_indices = np.where(errors)[0]
# Plot the first 25 misclassified examples
plt.figure(figsize=(10, 10))
for i in range(25):
index = misclassified_indices[i]
plt.subplot(5, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_test[index].reshape(28, 28), cmap=plt.cm.binary)
plt.xlabel(f"True: {y_true[index]}, Pred: {y_pred_classes[index]}")
plt.show()
Visualisasi Contoh yang Salah Diprediksi: Kita identifikasi contoh yang salah diprediksi dengan dengan melakukan plotting pada 25 gambar dengan label asli, dan hasil prediksi. Visualisasi ini membantu dalam mendiagnosis masalah pada model.

Penutup
Dalam artikel ini, kita telah berkenalan dengan computer vision dengan membuat model untuk mengklasifikasikan dataset MNIST menggunakan Keras. Berikut adalah langkah-langkah yang telah kita lalui:
Pengenalan Keras: Menjelaskan keunggulan dan kemudahan penggunaan Keras dalam membangun model deep learning.
Persiapan Data: Mengimpor dataset MNIST, melakukan normalisasi, dan mempersiapkan data untuk pelatihan dan pengujian.
Visualisasi Data: Memvisualisasikan gambar-gambar dalam dataset untuk memahami karakteristik data.
Pembuatan Model: Membangun model dengan lapisan-lapisan konvolusional, pooling, flatten, dropout, dan dense.
Melatih Model: Menyusun dan melatih model pada data pelatihan, serta memantau akurasi dan loss selama pelatihan.
Mengevaluasi Model: Mengevaluasi kinerja model pada data pengujian untuk mengukur akurasi dan loss.
Visualisasi Data yang Salah Diprediksi: Mengidentifikasi dan memvisualisasikan contoh-contoh yang salah diprediksi untuk memahami kelemahan model.
Model yang kita bangun menunjukkan hasil yang baik dengan akurasi pengujian lebih dari 99%. Namun, visualisasi dari contoh-contoh yang salah diprediksi memberikan wawasan tambahan tentang area di mana model mungkin perlu diperbaiki. Dengan pendekatan ini, kita dapat terus memperbaiki dan mengoptimalkan model untuk kinerja yang lebih baik. Pepatah mengatakan "A journey of thousand miles begins with a single step". Berawal dari tutorial dalam artikel ini, diharapkan kita bisa terus belajar tentang bagaimana membangun, melatih, dan mengevaluasi model, serta pentingnya visualisasi data dalam proses pengembangan model machine learning. Selamat mencoba dan semoga bermanfaat!
Referensi : https://keras.io/examples/vision/mnist_convnet/