


Pendahuluan
Kode:
Klasifikasi gambar merupakan salah satu pemanfaatan yang paling umum dari deep learning. Cakupan penerapan yang begitu luas berbanding lurus dengan kompleksitas data-data yang digunakan. Rumitnya karakteristik data yang ada seringkali menyebabkan kita kesulitan untuk membuat model yang bisa melakukan klasifikasi dengan baik. Sehingga terkadang untuk bisa melatih model yang optimal memerlukan waktu yang tidak sedikit.
Maka dari itu, salah satu teknik yang banyak digunakan untuk menghindari problem demikian adalah dengan melakukan transfer learning, di mana model yang telah dilatih pada dataset berukuran besar seperti ImageNet digunakan kembali untuk tugas-tugas spesifik lainnya. Sebagai contoh, pada projek ini kita akan menggunakannya untuk melakukan klasifikasi nasi padang.
Transfer learning memungkinkan kita untuk memanfaatkan pengetahuan yang telah dipelajari oleh model tersebut. Sehingga kita bisa menghemat waktu dan sumber daya komputasi, sekaligus meningkatkan kinerja model pada dataset yang baru. Pada projek ini, kita akan menerapkan transfer learning dengan model Vision Transformer (ViT). Berbeda dengan arsitektur pada umumnya yang menggunakan Convolutional Neural Network (CNN), ViT memanfaatkan pendekatan transformer yang awalnya dikembangkan untuk pemrosesan bahasa alami (Natural Language Processing). Model ViT memecah gambar menjadi patch-patch kecil dan memperlakukan setiap patch sebagai "token", hal ini mirip dengan kata-kata dalam teks. Dengan menggunakan lapisan transformer, ViT mampu menangkap hubungan spasial dan konteks di antara patch-patch ini, menghasilkan representasi yang kaya dan mendetail dari gambar.
Pada projek ini, kita akan menggunakan dataset "Padang Cuisine" dari Faldo Fajri Afrinanto yang tersedia di Kaggle. Dataset ini terdiri dari 9 kelas yaitu Rendang Daging Sapi, Pop Ayam, Ayam Goreng, Dendeng Batokok, Kari Ikan, Kari Tambusu, Kari Tunjang, Telur Balado, dan Omelet Padang dengan total keseluruhan sejumlah 993 gambar . Rendang sendiri cukup populer di kalangan internasional karena dinobatkan sebagai salah satu makanan paling lezat di dunia oleh sejumlah media populer.
Dataset Citation
Faldo Fajri Afrinanto. (2022). Padang Cuisine (Indonesian Food Image Dataset) [Data set]. Kaggle. https://doi.org/10.34740/KAGGLE/DSV/4053613
Impor Library
import os
import torch
import shutil
import numpy as np
from torch import nn
from tqdm import tqdm
import seaborn as sns
from torchinfo import summary
import matplotlib.pyplot as plt
from torchvision.io import read_image
from torchvision import transforms, datasets
from sklearn.model_selection import train_test_split
from torchvision.models import vit_b_16, ViT_B_16_Weights
from torchvision.transforms.functional import to_pil_image
from sklearn.metrics import confusion_matrix, classification_report
device = "cuda" if torch.cuda.is_available() else "cpu"
Pertama-tama adalah mengimpor library-library yang diperlukan. Terdapat cukup banyak library yang diperlukan untuk Projek ini. Secara garis besar kita akan menggunakan PyTorch untuk membuat model. Setelah mengimpor semua library yang diperlukan kita juga mengecek apakah GPU tersedia pada komputer yang kita gunakan.
Persiapan Data
Jika kita belum memiliki data yang diperlukan, kita bisa mengunduhnya dari kaggle. Sebelum mengunduh dari kaggle terlebih dahulu diperlukan kredensial, tutorial untuk mendapatkannya bisa anda dapatkan di sini. Setelah memiliki file key, jika kita menggunakan google colab kita bisa menggunakan kode di bawah ini:
!pip install -q kaggle
from google.colab import files
files.upload()
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download -d faldoae/padangfood
!unzip padangfood.zip -d padangfood
Pertama, !pip install -q kaggle digunakan untuk menginstal library Kaggle di lingkungan Colab. Setelah itu, from google.colab import files dan files.upload() memungkinkan kita untuk mengunggah kaggle.json, yang berisi kredensial API Kaggle ke Colab. Kemudian, direktori ~/.kaggle dibuat dengan !mkdir -p ~/.kaggle, lalu kaggle.json disalin ke direktori tersebut dengan !cp kaggle.json ~/.kaggle/. Selanjutnya adalah mengatur perizinan file dengan !chmod 600 ~/.kaggle/kaggle.json. Terakhir adalah mengunduh dataset dari kaggle menggunakan !kaggle datasets download -d faldoae/padangfood. Kemudian kode !unzippadangfood.zip-d padangfood digunakan untuk mengekstrasi data yang telah diunduh agar bisa digunakan.
Jika memperhatikan struktur file pada dataset, bisa kita temukan bahwa dataset belum terbagi-bagi menjadi data latih dan validasi, melainkan hanya berdasarkan kategori makanan. Sedangakn hal tersebut diperlukan untuk keperluan image classification yang memerlukan kumpulan data terpisah untuk melatih model dan memvalidasi performanya.Untuk itu, kita perlu melakukan splitting secara manual.
def copy_files(files, dest_dir):
os.makedirs(dest_dir, exist_ok=True)
for file in files:
shutil.copy(file, dest_dir)
dataset_dir = '/content/padangfood/dataset_padang_food'
train_dir = '/content/dataset/train'
val_dir = "/content/dataset/val"
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
for category in os.listdir(dataset_dir):
if not os.path.isdir(os.path.join(dataset_dir, category)):
continue
files = os.listdir(os.path.join(dataset_dir, category))
file_paths = [os.path.join(dataset_dir, category, file) for file in files]
train_files, val_files = train_test_split(file_paths, test_size=0.3, random_state=42, stratify=None)
copy_files(train_files, os.path.join(train_dir, category))
copy_files(val_files, os.path.join(val_dir, category))
Terlebih dahulu kita membuat fungsi copy_files untuk menyalin daftar file ke direktori tujuan yang ditentukan. Kemudian, kita juga mendefinisikan variabel berisi alamat direktori dataset (dataset_dir )serta direktori tujuan untuk data latih (train_dir) dan validasi (val_dir). Selanjutnya, kita melakukan looping pada setiap kategori makanan di dalam direktori dataset. Ini dilakukan untuk mendapatkan filepath lengkap dari setiap file agar. File-file ini kemudian dibagi menjadi set pelatihan dan validasi dengan rasio 70:30 menggunakan train_test_split, memastikan bahwa pembagian ini dapat direproduksi dengan random_state=42. Fungsi copy_files kemudian digunakan untuk menyalin file pelatihan dan validasi ke direktori masing-masing.
Visualisasi Dataset
Agar lebih bisa memahami data yang digunakan, kita bisa melakukan visualisasi dari gambar-gambar yang terdapat di dalamnya. Pada projek ini kita membuat fungsi khusus visualize_images untuk memvisualisasikan sampel gambar dari dataset yang telah diklasifikasikan ke dalam beberapa kelas.
def visualize_images(dataset, class_names, samples_per_class=4):
plt.figure(figsize=(20, len(class_names) * 5))
for i, class_name in enumerate(class_names):
class_indices = [idx for idx, (_, label) in enumerate(dataset.samples) if dataset.classes[label] == class_name]
selected_indices = np.random.choice(class_indices, size=samples_per_class, replace=False)
for j, idx in enumerate(selected_indices, start=1):
subplot_index = i * samples_per_class + j
plt.subplot(len(class_names), samples_per_class, subplot_index)
image, label = dataset[idx]
image = np.array(image)
plt.imshow(image)
plt.title(f"Class: {class_name}")
plt.axis('off')
plt.tight_layout()
plt.show()
dataset = datasets.ImageFolder(root=train_dir)
visualize_images(dataset, dataset.classes, samples_per_class=4)
Di sini kita memuat dataset menggunakan datasets.ImageFolder, dan kemudian memanggil fungsi visualize_images dipanggil untuk memvisualisasikan 4 sampel per kelas dari dataset tersebut.

Augmentasi Data
Tahap selanjutnya adalah melakukan augmentasi data melibatkan berbagai teknik transformasi seperti pengubahan ukuran, pemotongan secara acak, serta rotasi gambar baik secara horizontal dan vertikal. Augmentasi dilakukan untuk memperkaya dataset dengan variasi gambar yang berbeda-beda, sehingga membantu model untuk belajar dari data yang lebih bervariasi dan mencegah overfitting.
train_transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
train_dataset = datasets.ImageFolder(root=train_dir, transform=train_transform)
val_dataset = datasets.ImageFolder(root=val_dir, transform=val_transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=2)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=2)
Kode transform.compose diterapkan untuk melakukan transformasi data untuk dataset pelatihan dan validasi, transformasi pada data latih lebih kompleks untuk meningkatkan variasi melalui augmentasi, hal ini berguna untuk membantu model belajar dan mencegah overfitting. Adapun pada data validasi transformasi lebih sederhana untuk memastikan evaluasi yang konsisten dan representatif. Dataset pelatihan dan validasi kemudian dimuat menggunakan datasets.ImageFolder dengan transformasi yang telah ditentukan. Terakhir, DataLoader dibuat untuk dataset pelatihan dengan batch size 32. Pengacakan data (shuffle) dalam train loader untuk memastikan bahwa model tidak belajar urutan spesifik dari data latih, karena hal tersebut bisa menyebabkan bias.

Persiapan Model
Setelah data siap, tahap selanjutnya adalah melatih model. Pada projek ini kita akan menggunakan model Vision Transformer.
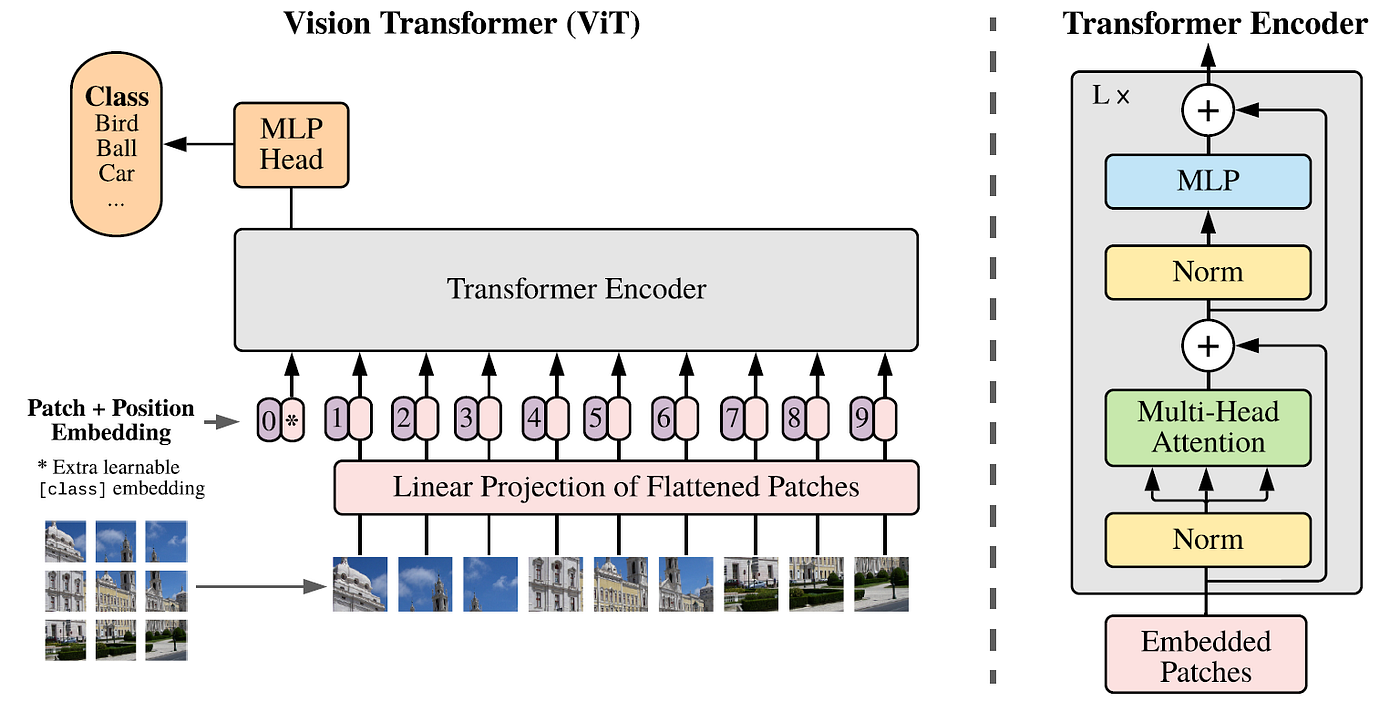
weights = ViT_B_16_Weights.IMAGENET1K_SWAG_LINEAR_V1
model = vit_b_16(weights=weights).to(device)
Pertama-tama kita memuat bobot dari model vision transformer dengan ViT_B_16_Weights.IMAGENET1K_SWAG_LINEAR_V1. Bobot ini telah dilatih pada dataset ImageNet1K dengan teknik SWAG (Stochastic Weight Averaging-Gaussian) yang bertujuan untuk meningkatkan kemampuan generalisasi model. Dengan menggunakan bobot yang telah dilatih sebelumnya, model dapat memanfaatkan fitur-fitur general yang sebelumnya telah dipelajari pada dataset besar, sehingga mengurangi waktu dan sumber daya yang diperlukan untuk melatih model dari awal.
for param in model.conv_proj.parameters():
param.requires_grad = False
for param in model.encoder.parameters():
param.requires_grad = False
model.heads = torch.nn.Sequential(
torch.nn.Dropout(p=0.2, inplace=True),
torch.nn.Linear(in_features=768,
out_features=9,
bias=True)).to(device)
Selanjutnya adalah menyesuaikan model pretrained agar sesuai dengan tugas klasifikasi makanan Padang. Pertama, kita perlu membekukan sejumlah layer dari model yang kita gunakan. Hal ini karena layer-layer tersebut sebelumnya telah dilatih pada dataset yang lebih besar dan beragam, sehingga mereka sudah mampu mengenali pola-pola dasar dalam gambar. Dengan membekukannya, kita dapat memanfaatkan kemampuan ini tanpa perlu melatih ulang seluruh model dari awal, yang akan membutuhkan lebih banyak data dan waktu. Selain itu, dengan membekukan sebagian besar layer dan hanya melatih classifier, model dapat lebih cepat beradaptasi untuk mengklasifikasikan dataset spesifik (dalam hal ini, gambar makanan Padang) tanpa mengubah fitur-fitur dasar yang telah dipelajari. Parameter-parameter yang dibekukan adalah layer conv_proj dan encoder . Pembekuan dilakukan dengan mengatur requires_grad menjadi False. Ini berarti parameter-parameter ini tidak akan diperbarui selama proses pelatihan.
Selanjutnya, lapisan klasifikasi model diubah dengan membuat ulang lapisan heads menggunakan torch.nn.Sequential. Lapisan baru ini terdiri dari dua bagian:
Dropout Layer: Lapisan dropout dengan probabilitas 0.2, yang membantu mencegah overfitting dengan secara acak menonaktifkan 20% unit selama pelatihan.
Linear Layer: Lapisan linear dengan 768 unit input dan 9 unit output, sesuai dengan jumlah kelas dalam dataset makanan Padang.
Setelah model siap, kita bisa melihat ringkasan model dengan menjalankan kode di bawah ini
summary(model=model,
input_size=(32, 3, 224, 224),
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"])
Dengan menjalankan kode di atas, kita bisa mendapatkan ringkasan model yang mencakup informasi penting tentang setiap layer, seperti dimensi input dan output, jumlah parameter, dan status parameter.

Gambar 4: Summary model.
Pelatihan Model
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
def train_one_epoch(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
correct = 0
total = 0
progress_bar = tqdm(enumerate(train_loader), total=len(train_loader), desc="Training", ncols=100)
for batch_idx, (inputs, labels) in progress_bar:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
train_loss = running_loss / (batch_idx + 1)
train_accuracy = correct / total
progress_bar.set_postfix(Loss=f'{train_loss:.4f}', Accuracy=f'{100 * train_accuracy:.2f}%', refresh=True)
return train_loss, train_accuracy
def evaluate_model(model, val_loader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
all_predicted = []
all_labels = []
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
all_predicted.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
val_loss = running_loss / len(val_loader)
val_accuracy = correct / total
return val_loss, val_accuracy, np.array(all_predicted), np.array(all_labels)
Sebelum melatih model terlebih dahulu kita perlu mendifinisikan loss dan optimizer terlebih dahulu. Fungsi loss Cross Entropy diinisiasi dengan nn.CrossEntropyLoss(), jenis loss function ini umum digunakan untuk tugas klasifikasi multi-kelas. Selanjutnya menginisialisasi optimizer Adam dengan torch.optim.Adam(model.parameters(), lr=0.001). Optimizer ini diterapkan pada parameter model dan learning rate yang digunakan adalah 0.001, angka learning rate kecil umum digunakan ketika melakukan transfer learning.
Untuk menerapkan proses pelatihan kita membuat fungsi train_one_epoch dan evaluate_model . Fungsi train_one_epoch digunakan untuk melatih model dalam satu epoch penuh. Di awal dengan model.train() kita mengatur model agar berada pada mode pelatihan. Kemudian kita membuat progress_bar agar proses pelatihan bisa terpantau dengan lebih interaktif. Di dalam setiap epoch, kita melakukan loop pada setiap batch di dalam train_loader. Di awal kita membersihkan gradien dengan optimizer.zero_grad(). Kemudian mendapatkan prediksi model dengan melakukan forward pass dengan outputs = model(inputs). Nilai loss antara prediksi dan label kemudian didapatkan dengan loss = criterion(outputs, labels) . Selanjutnya loss.backward() melakukan backpropagation untuk menghitung gradien, dari gradien yang didapatkan kemudian bobot diperbarui dengan optimizer.step(). Output dari fungsi train_one_epoch berupa rata-rata loss dan akurasi untuk satu epoch.
Fungsi evaluate_model digunakan untuk mengevaluasi performa model pada dataset validasi. Tahap awal adalah kita mengatur model ke mode evaluasi dengan model.eval(). Selanjutnya with torch.no_grad() akan menonaktifkan perhitungan gradien, karena pada tahap ini kita tidak akan memperbarui bobot. Selanjutnya adalah melakukan looping pada setiap batch di dalam val_loader. Di sini kita melakukan forward pass untuk mendapatkan prediksi model dengan outputs = model(inputs). Lalu juga menghitung loss antara prediksi dan label dengan loss = criterion(outputs, labels). Total loss dan akurasi untuk batch saat ini kemudian diakumulasikan dan outputnya akhir dari evaluate_model berupa rata-rata loss, akurasi, prediksi, dan label untuk dataset validasi.
num_epochs = 25
train_losses, val_losses = []
train_accuracies, val_accuracies = []
for epoch in range(num_epochs):
train_loss, train_accuracy = train_one_epoch(model, train_loader, loss_fn, optimizer, device)
val_loss, val_accuracy, val_predicted, val_labels = evaluate_model(model, val_loader, loss_fn, device)
train_losses.append(train_loss)
val_losses.append(val_loss)
train_accuracies.append(train_accuracy)
val_accuracies.append(val_accuracy)
print(f"\nEpoch {epoch+1}/{num_epochs} Summary:")
print(f"Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.4f}")
print(f"Val Loss: {val_loss:.4f}, Val Accuracy: {val_accuracy:.4f}\n")
Setelah fungsi-fungsi yang diperlukan siap, selanjutnya adalah memulai proses pelatihan. Pada projek ini, kita mengatur proses pelatihan selama 25 epoch, yang mana pada setiap epoch kita akan menampilkan kinerja model pada data latih dan validasi. Pertama-tama, kita menginisialisasikan num_epochs menjadi 25. Lalu membuat list yang kemudian berguna untuk melacak nilai loss dan akurasi pada setiap epoch.
Dalam setiap epoch, kita akan memanggil fungsi train_one_epoch untuk melatih model pada dataset pelatihan, dimana outputnya berupa loss dan akurasi pada data latih. Selanjutnya juga memanggil fungsi evaluate_model untuk mengevaluasi model pada dataset validasi. Di akhir proses pada tiap epoch, ringkasan hasil berupa loss dan akurasi pada tiap data ditampilkan. Proses ini diulang terus-menerus pada setiap epoch sampai memenuhi jumlah epoch yang diinginkan.
Visualisasi Data
Setelah tahap pelatihan, kita bisa membuat visualisasi untuk menganalisis hasil yang didapatkan.
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_accuracies, label='Train Accuracy')
plt.plot(val_accuracies, label='Validation Accuracy')
plt.title('Training vs Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_losses, label='Train Loss')
plt.plot(val_losses, label='Validation Loss')
plt.title('Training vs Validation Loss')
plt.legend()
plt.show()
Dengan kode di atas, kita membuat dua grafik yang membandingkan akurasi dan loss antara data pelatihan dan validasi selama 25 epoch. Subplot pertama menampilkan grafik akurasi pelatihan dan validasi dan subplot kedua menampilkan grafik loss pelatihan dan validasi. Output dari kode di atas adalah gambar sebagai berikut:

Berdasarkan gambar di atas, kita bisa melihat bahwa grafik akurasi meningkat secara signifikan hingga di atas 90% di awal-awal pelatihan kemudian stabil setelah beberapa epoch. Begitu juga dengan grafik loss yang menurun dengan cepat di awal-awal epoch. Hal ini merupakan kelebihan dari transfer learning yang kita gunakan, di mana model bisa memperoleh hasil akurasi dan loss yang baik sejak awal-awal pelatihan. Berbeda dengan melatih model dari 0 yang seringkali memerlukan jumlah epoch yang sangat besar agar bisa mendapatkan hasil yang baik. Dari hasil ini juga bisa diketahui bahwa model Vision Transformer (ViT) mampu beradaptasi dengan baik pada dataset makanan Padang.
Kita juga akan membuat confusion matrix dari hasil prediksi model pada data validasi. Ini dilakukan mendapatkan insight lebih dalam terkait performa model pada setiap label yang ada di dalam dataset.
class_names = train_dataset.classes
def plot_confusion_matrix(cm, class_names):
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=class_names, yticklabels=class_names)
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.title('Confusion Matrix')
plt.show()
cm = confusion_matrix(val_labels, val_predicted)
plot_confusion_matrix(cm, class_names)
Hasil dari kode di atas adalah confusion matrix sebagai berikut:

Hasil di atas menunjukkan bahwa sebagian besar gambar berhasil diklasifikasikan dengan benar. Namun, ada beberapa kesalahan klasifikasi, seperti ayam_goreng yang terkadang diprediksi sebagai ayam_pop ataupun gulai_ikan yang beberapa kali diprediksi sebagai gulai_tambusu dan gulai_tunjang. Sejumlah kesalahan ini mungkin terjadi karena adanya kesamaan visual antara beberapa jenis makanan yang sulit dibedakan oleh model. Selain dengan confusion matrix, kita juga bisa melakukan analisa lebih lanjut dengan membuat classification report untuk melihat nilai precision, recall, dan f1-score.
report = classification_report(val_labels, val_predicted, target_names=class_names)
print(report)
Hasilnya adalah sebagai berikut:
precision recall f1-score support
ayam_goreng 1.00 0.97 0.98 33
ayam_pop 0.97 1.00 0.99 34
daging_rendang 0.94 1.00 0.97 32
dendeng_batokok 0.94 0.97 0.96 33
gulai_ikan 0.94 0.91 0.93 34
gulai_tambusu 0.88 0.90 0.89 31
gulai_tunjang 0.86 0.86 0.86 36
telur_balado 1.00 0.91 0.95 34
telur_dadar 1.00 1.00 1.00 35
accuracy 0.95 302
macro avg 0.95 0.95 0.95 302
weighted avg 0.95 0.95 0.95 302
Secara keseluruhan, model menunjukkan performa yang sangat baik dengan precision, recall, dan F1-score yang tinggi di sebagian besar kelas. Hanya pada beberapa kelas seperti gulai_tambusu dan gulai_tunjang yang memiliki metrik yang sedikit lebih rendah, yang mana mungkin disebabkan karena adanya kesamaan visual atau variasi yang lebih sulit dideteksi oleh model. Namun, dengan akurasi keseluruhan 95%, model ini cukup andal dalam mengklasifikasikan makanan Padang. Untuk analisa tambahan kita bisa menampilkan gambar-gambar dari makanan yang salah diprediksi oleh model seperti berikut:

Dari gambar di atas bisa kita lihat sekilas bahwa memang ada kemiripan visual antar gambar, seperti makanan gulai yang memang secara umum memiliki kuah kental.
Kesimpulan
Dari projek ini, kita sudah berlatih menerapkan transfer learning dengan menggunakan model Vision Transformer untuk klasifikasi makanan padang. Performa yang didapatkan cukup baik dengan akurasi mencapai 95%. Dari hasil yang didapatkan juga bisa dilihat bahwa transfer learning efektif untuk pelatihan model dalam waktu yang lebih singkat. Untuk pengembangannya, kita bisa mengeksplorasi teknik augmentasi data yang lebih bervatiasi, ataupun menggunakan dataset yang lebih besar dan beragam, teknik fine-tuning yang lebih fokus pada layer tertentu, sampai menguji arsitektur model lain yang mungkin lebih cocok. Dengan langkah-langkah ini, diharapkan kinerja bisa mendapatkan model yang lebih andal dalam berbagai kondisi dan variasi data.